
Creating a Kafka cluster that is efficient and resilient is not a simple task. It requires a clear understanding of many components and their interdependencies. In this blog post, we’re going to walk you through the essentials of setting up a Kafka cluster, highlighting the key things you’ll need.
1. Essential Components for a Kafka Cluster Setup
Here are some key components that you need to have to properly set up a Kafka cluster:
1.1 Zookeeper Cluster
Zookeeper is a distributed, open-source coordination service for distributed applications. It maintains configuration information, provides distributed synchronization, and allows groups to function effectively. A Kafka cluster heavily relies on Zookeeper for maintaining and managing crucial tasks.
1.2 Kafka Cluster
A Kafka cluster is a system that consists of multiple Kafka brokers. Each broker allows the system to balance the load and ensure data redundancy.
1.3 Proper Replication Factor
The replication factor is the number of times a data is copied and stored in different Kafka brokers. This ensures the data is not lost in case of broker failures.
1.4 Multi Availability Zones Setup
A Multi-Availability-Zone setup means the Kafka Cluster is spread across multiple zones. This is beneficial for load balancing and ensuring the system’s high availability.
1.5 Proper Configurations
Proper configurations mean setting up Kafka and Zookeeper in such a way that they are optimized for your specific use case. This includes configuring the right amount of memory, storage, and CPU resources, among others.
1.6 Administration Tools
Administration tools help manage your Kafka cluster, monitor performance, and debug any issues.
2. Architecture
Kafka architecture consists of topics, producers, consumers, brokers, logs, partitions, and replicas. For an efficient Kafka production deployment, it’s recommended to have different servers for Zookeepers.
Currently, the stable release channel for Kafka is 3.4.x. Therefore, it’s advisable to use this for your deployments. Avoid using the 3.5.x version as it’s still in beta.
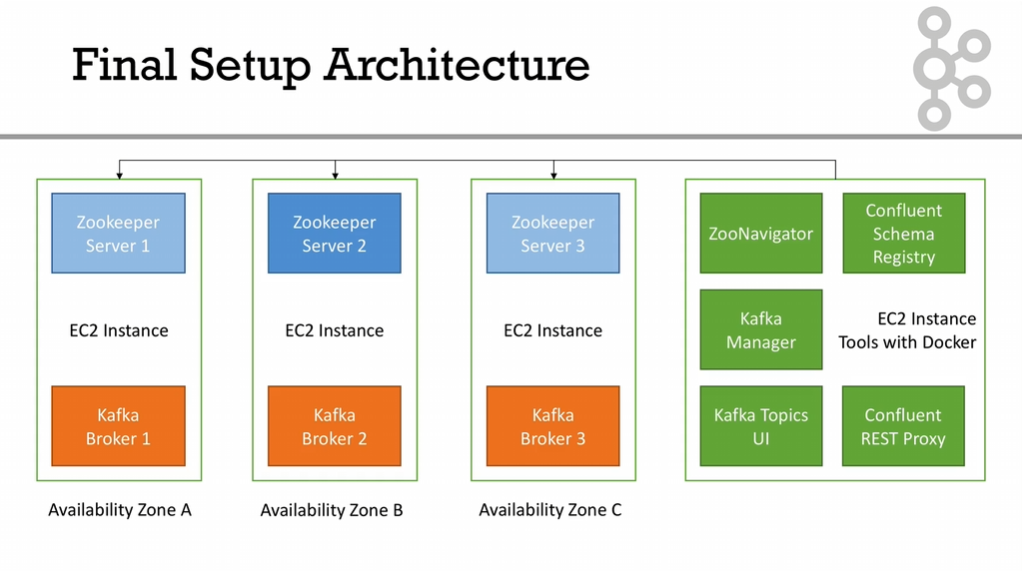
3. Zookeeper Production Deployment
When deploying Zookeeper in production, there are certain key considerations to keep in mind:
3.1 Sizing
In terms of the number of servers, you need an odd number, such as 1, 3, 5, 7, 9, with 3 typically being sufficient for most setups.
3.2 Configuration
A recommended configuration for a Zookeeper server is 2 vCPU, 4 RAM, and a 50GB disk. This configuration can be adjusted based on your specific needs and usage patterns.
4. Zookeeper Installation
To install Zookeeper, you can follow the official Apache documentation found here or follow the tutorial available on TutorialsPoint. For advanced settings and administrative tasks, refer to the Zookeeper Admin guide.
4.1 Installing Essential Packages
To get started, we need to install some essential packages that are required for Zookeeper and Kafka. Run the following command:
sudo apt-get update && \
sudo apt-get -y install wget ca-certificates zip net-tools vim nano tar netcat4.2 Installing Java Open JDK 8
Kafka and Zookeeper both require Java to run. Here, we’ll install Open JDK 8 using the following commands:
sudo apt-get -y install openjdk-8-jdk
java -versionThe java -version command is used to verify that Java has been installed correctly.
4.3 Disabling RAM Swap
In some Linux distributions, it’s recommended to disable RAM swapping to ensure optimal performance. You can do so by adjusting the system’s ‘swappiness’ parameter:
sudo sysctl vm.swappiness=1
echo 'vm.swappiness=1' | sudo tee --append /etc/sysctl.conf4.4 Adding Hosts Entries
Adding hosts entries can be useful for simulating DNS, especially for local testing. You need to replace the IPs below with the relevant IPs for your setup:
echo "172.31.9.1 kafka1
172.31.9.1 zookeeper1
172.31.19.230 kafka2
172.31.19.230 zookeeper2
172.31.35.20 kafka3
172.31.35.20 zookeeper3" | sudo tee --append /etc/hosts4.5 Downloading Zookeeper and Kafka
Now, we are going to download Zookeeper and Kafka. For Kafka, version 0.10.2.1 and Scala 2.12 are recommended:
wget https://archive.apache.org/dist/kafka/0.10.2.1/kafka_2.12-0.10.2.1.tgz
tar -xvzf kafka_2.12-0.10.2.1.tgz
rm kafka_2.12-0.10.2.1.tgz
mv kafka_2.12-0.10.2.1 kafka
cd kafka/4.6 Zookeeper Quickstart
Lastly, to ensure that Zookeeper is functioning correctly, you can start it and check its configuration with the following commands:
cat config/zookeeper.properties
bin/zookeeper-server-start.sh config/zookeeper.propertiesIf Zookeeper starts successfully and binds to port 2181, then everything is set up correctly. You can use Ctrl+C to exit.
Validating Your Zookeeper Installation
Now that we’ve installed Zookeeper, it’s essential to verify its installation and ensure it’s running correctly.
4.7 Testing Zookeeper Installation
4.7.1 Start Zookeeper in the Background
To initiate Zookeeper in the background and check the root of your Zookeeper filesystem, use the following commands:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
bin/zookeeper-shell.sh localhost:2181
ls /4.7.2 Demonstrate the Use of a 4 Letter Word
The four-letter words are commands that you can use to interact with Zookeeper. They are served at the client port. Here, we are using “ruok”, which checks if Zookeeper is running in a non-error state:
echo "ruok" | nc localhost 2181 ; echo4.8 Install Zookeeper Boot Scripts
To ensure Zookeeper starts automatically upon system boot, create a new Zookeeper service file:
sudo nano /etc/init.d/zookeeper
sudo chmod +x /etc/init.d/zookeeper
sudo chown root:root /etc/init.d/zookeeperPaste the following script into the file:
#!/bin/sh
#
# zookeeper Start/Stop zookeeper
#
# chkconfig: - 99 10
# description: Standard script to start and stop zookeeper
DAEMON_PATH=/home/ubuntu/kafka/bin
DAEMON_NAME=zookeeper
PATH=$PATH:$DAEMON_PATH
# See how we were called.
case "$1" in
start)
# Start daemon.
pid=`ps ax | grep -i 'org.apache.zookeeper' | grep -v grep | awk '{print $1}'`
if [ -n "$pid" ]
then
echo "Zookeeper is already running";
else
echo "Starting $DAEMON_NAME";
$DAEMON_PATH/zookeeper-server-start.sh -daemon /home/ubuntu/kafka/config/zookeeper.properties
fi
;;
stop)
echo "Shutting down $DAEMON_NAME";
$DAEMON_PATH/zookeeper-server-stop.sh
;;
restart)
$0 stop
sleep 2
$0 start
;;
status)
pid=`ps ax | grep -i 'org.apache.zookeeper' | grep -v grep | awk '{print $1}'`
if [ -n "$pid" ]
then
echo "Zookeeper is Running as PID: $pid"
else
echo "Zookeeper is not Running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
exit 1
esac
exit 0To ensure the script runs at startup, execute:
sudo update-rc.d zookeeper defaults4.8.1 Stop Zookeeper
You can stop Zookeeper by using the following command:
sudo service zookeeper stop4.8.2 Verify It’s Stopped
Confirm that Zookeeper has stopped with:
nc -vz localhost 21814.8.3 Start Zookeeper
You can restart Zookeeper with the following command:
sudo service zookeeper start4.8.4 Verify It’s Started
Confirm that Zookeeper has started and is running correctly:
nc -vz localhost 2181
echo "ruok" | nc localhost 2181 ; echo4.8.5 Check the Logs
Finally, always check the logs to ensure there are no hidden issues:
cat logs/zookeeper.out4.9 Zookeeper Quorum Setup
To achieve high availability and tolerance for failures, ZooKeeper servers are usually set up in a cluster, known as an “ensemble” or “quorum”.
Use the following commands to setup a Zookeeper quorum:
#!/bin/bash
# create data dictionary for zookeeper
sudo mkdir -p /data/zookeeper
sudo chown -R ubuntu:ubuntu /data/
# declare the server's identity
echo "1" > /data/zookeeper/myid
# edit the zookeeper settings
rm /home/ubuntu/kafka/config/zookeeper.properties
nano /home/ubuntu/kafka/config/zookeeper.properties
# restart the zookeeper service
sudo service zookeeper stop
sudo service zookeeper start
# observe the logs - need to do this on every machine
cat /home/ubuntu/kafka/logs/zookeeper.out | head -100
nc -vz localhost 2181
nc -vz localhost 2888
nc -vz localhost 3888
echo "ruok" | nc localhost 2181 ; echo
echo "stat" | nc localhost 2181 ; echo
bin/zookeeper-shell.sh localhost:2181
# not happy
ls /And your zookeeper.properties file should look like:
# the location to store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
dataDir=/data/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# the basic time unit in milliseconds used by ZooKeeper. It is used to do heartbeats and the minimum session timeout will be twice the tickTime.
tickTime=2000
# The number of ticks that the initial synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# zoo servers
# these hostnames such as `zookeeper-1` come from the /etc/hosts file
server.1=zookeeper1:2888:3888
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2888:38884.10 Zookeeper 4 Letter Words
Four-letter words are commands that you can use to interact with Zookeeper. They are served at the client port. To learn more about these commands, you can refer to the official documentation.
Here are a few examples of how to use these commands:
#!/bin/bash
# https://zookeeper.apache.org/doc/r3.4.8/zookeeperAdmin.html#sc_zkCommands
# conf
# New in 3.3.0: Print details about serving configuration.
echo "conf" | nc localhost 2181
...
...
echo "mntr" | nc localhost 21814.11 Zookeeper Internal File System
Zookeeper has an internal file system that you should not modify. The myid file is the only exception, which you can use to set the server’s id. The rest of the files are managed by Zookeeper itself.
- myid: file representing the server id. That’s how Zookeeper knows its identity.
- version-2/: folder that holds the zookeeper data.
- AcceptEpoch and CurrentEpoch: internal to Zookeeper.
- Log.X: Zookeeper data files.
4.12 Zookeeper Performance
The performance of Zookeeper is critical to the overall performance of your distributed system. Here are some tips to optimize Zookeeper’s performance:
- Minimize latency as much as possible.
- Use Fast Disks (like SSD) for storage.
- Avoid RAM Swap to prevent performance degradation.
- Use separate disks for snapshots and logs to maximize IO performance.
- Ensure high performance network (low latency).
- Keep a reasonable number of Zookeeper servers to balance between availability and performance.
- Isolate Zookeeper instances from other processes (for example, run separate instances for Zookeeper and Kafka) to prevent resource contention.
4.13 Tools Setup
Before you can start using Zookeeper and Kafka, you’ll need to install the necessary tools. Here, we’ll use Docker as the container platform to run Zookeeper and Kafka. We choose Docker because it allows us to isolate applications in containers, making it easier to manage dependencies and ensure our application runs the same way in every environment.
Here are the steps to install Docker and Docker Compose:
#!/bin/bash
sudo apt-get update
# Install packages to allow apt to use a repository over HTTPS:
sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
# Add Docker’s official GPG key:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# set up the stable repository.
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# install docker
sudo apt-get update
sudo apt-get install -y docker-ce docker-compose
# give ubuntu permissions to execute docker
sudo usermod -aG docker $(whoami)
# log out
exit
# log back in
# make sure docker is working
docker run hello-worldFor a multi-node setup, you may need to add hosts entries to your /etc/hosts file. This is necessary when you don’t have a DNS setup, or you want to mock a DNS for development purposes. Here’s how to add hosts entries:
# Add hosts entries (mocking DNS) - put relevant IPs here
echo "172.31.9.1 kafka1
172.31.9.1 zookeeper1
172.31.19.230 kafka2
172.31.19.230 zookeeper2
172.31.35.20 kafka3
172.31.35.20 zookeeper3" | sudo tee --append /etc/hostsRemember to replace the IPs with the actual IPs of your Kafka and Zookeeper servers. The hostnames (kafka1, kafka2, etc.) are the names that your applications will use to connect to the Kafka and Zookeeper servers.
5. Kafka Installations
5.1 Kafka Sizing
The size of your Kafka cluster will depend on your workload and performance requirements. Here’s a general guideline for Kafka cluster sizing:
- Separate Zookeeper nodes: Ideally, run at least three Zookeeper nodes for a fault-tolerant setup.
- Kafka Brokers: Minimum of three Kafka brokers for a production environment. This ensures that you have a fault-tolerant system and can handle a broker failing.
- Replication Factor: A replication factor of 3 is generally sufficient for most clusters.
- Scalability: Kafka scales horizontally, so add more brokers to your cluster when the bottleneck is reached (e.g., network, disk I/O, CPU, RAM).
5.2 Kafka Configuration
For configuring Kafka, refer to the official Kafka documentation at Kafka Broker Configs.
Here’s an example of the server.properties file:
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# change your.host.name by your machine's IP or hostname
advertised.listeners=PLAINTEXT://kafka1:9092
# Switch to enable topic deletion or not, default value is false
delete.topic.enable=true
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/data/kafka
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=8
# we will have 3 brokers so the default replication factor should be 2 or 3
default.replication.factor=3
# number of ISR to have in order to minimize data loss
min.insync.replicas=2
############################# Log Retention Policy #############################
# The minimum age of a log file to be eligible for deletion due to age
# this will delete data after a week
log.retention.hours=168
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################## Other ##################################
# I recommend you set this to false in production.
# We'll keep it as true for the course
auto.create.topics.enable=true5.3 Cluster Setup
Here’s a script to set up a Kafka broker. Make sure you repeat this on each of your broker machines.
#!/bin/bash
# Add file limits configs - allow to open 100,000 file descriptors
echo "* hard nofile 100000
* soft nofile 100000" | sudo tee --append /etc/security/limits.conf
sudo reboot
sudo service zookeeper start
sudo chown -R ubuntu:ubuntu /data/kafka
# edit the config
rm config/server.properties
# MAKE SURE TO USE ANOTHER BROKER ID
nano config/server.properties
# launch kafka - make sure things look okay
bin/kafka-server-start.sh config/server.properties
# Install Kafka boot scripts
sudo nano /etc/init.d/kafka
sudo chmod +x /etc/init.d/kafka
sudo chown root:root /etc/init.d/kafka
# you can safely ignore the warning
sudo update-rc.d kafka defaults
# start kafka
sudo service kafka start
# verify it's working
nc -vz localhost 9092
# look at the logs
cat /home/ubuntu/kafka/logs/server.log
# make sure to fix the __consumer_offsets topic
bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka --config min.insync.replicas=1 --topic __consumer_offsets --alter
# read the topic on broker 1 by connecting to broker 2!
bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092 --topic first_topic --from-beginning
# DO THE SAME FOR BROKER 3
# After, you should see three brokers here
bin/zookeeper-shell.sh localhost:2181
ls /kafka/brokers/ids
# you can also check the zoonavigator UI5.3.1 Kafka init file
To ensure Kafka starts as a service when the server starts, we need to create an init file. This is an example of such a script:
#!/bin/bash
#/etc/init.d/kafka
DAEMON_PATH=/home/ubuntu/kafka/bin
DAEMON_NAME=kafka
# Check that networking is up.
#[ ${NETWORKING} = "no" ] && exit 0
PATH=$PATH:$DAEMON_PATH
# See how we were called.
case "$1" in
start)
# Start daemon.
pid=`ps ax | grep -i 'kafka.Kafka' | grep -v grep | awk '{print $1}'`
if [ -n "$pid" ]
then
echo "Kafka is already running"
else
echo "Starting $DAEMON_NAME"
$DAEMON_PATH/kafka-server-start.sh -daemon /home/ubuntu/kafka/config/server.properties
fi
;;
stop)
echo "Shutting down $DAEMON_NAME"
$DAEMON_PATH/kafka-server-stop.sh
;;
restart)
$0 stop
sleep 2
$0 start
;;
status)
pid=`ps ax | grep -i 'kafka.Kafka' | grep -v grep | awk '{print $1}'`
if [ -n "$pid" ]
then
echo "Kafka is Running as PID: $pid"
else
echo "Kafka is not Running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
exit 1
esac
exit 05.3.2 advertised.listener setting
The advertised.listeners setting defines how clients will connect to the Kafka broker. This is important when setting up a Kafka cluster:
- If your clients are on your private network, set either:
- the internal private IP
- the internal private DNS hostname
- If your clients are on a public network, set either:
- The external Public IP
- The external public DNS hostname pointing to the public IP.
5.4 Cluster Management
A robust Kafka setup requires a toolset for managing and monitoring your Kafka cluster. One popular option is the Kafka Manager.
5.4.1 Kafka Manager
Kafka Manager is a tool for managing Apache Kafka. It allows you to view the state of your cluster, create topics, delete topics, view topic details, add partitions to topics, and more.
Here is a script to install Kafka Manager using Docker:
#!/bin/bash
# make sure you open port 9000 on the security group
# make sure you can access the zookeeper endpoints
nc -vz zookeeper1 2181
nc -vz zookeeper2 2181
nc -vz zookeeper3 2181
# make sure you can access the kafka endpoints
nc -vz kafka1 9092
nc -vz kafka2 9092
nc -vz kafka3 9092
# copy the kafka-manager-docker-compose.yml file
nano kafka-manager-docker-compose.yml
# launch it
docker-compose -f kafka-manager-docker-compose.yml up -dHere’s the Docker Compose file you need to run Kafka Manager:
version: '2'
services:
# https://github.com/yahoo/kafka-manager
kafka-manager:
image: qnib/plain-kafka-manager
network_mode: host
environment:
ZOOKEEPER_HOSTS: "zookeeper1:2181,zookeeper2:2181,zookeeper3:2181"
APPLICATION_SECRET: change_me_please
restart: alwaysNow, you should be able to open a web browser and go to http://<your-kafka-manager-host>:9000 to access the Kafka Manager interface.
5.5 Kafka Performance
When it comes to achieving optimal performance with Kafka, you need to consider the following factors:
5.5.1 Disk I/O
- Kafka performs sequential reads, therefore selecting a disk that performs well under these conditions is crucial.
- It is recommended to format your drive as XFS for optimal Kafka performance.
- If read/write throughput is a bottleneck, consider mounting multiple disks in parallel for Kafka using the configuration:
log.dirs=/disk1/kafka-logs,/disk2/kafka-logs.... - Kafka performance is independent of the volume of data stored in Kafka. Therefore, it is vital to ensure you expire data quickly enough (the default is one week) and monitor your disk performance.
5.5.2 Network
- To ensure low latency, your Kafka and Zookeeper instances should be geographically close. This means not placing one broker in Europe and another in the US.
- Locating two brokers on the same rack can enhance performance, but this could pose a significant risk if the rack goes down.
- Network bandwidth is critical in Kafka as the network will likely be your bottleneck. Ensure you have enough bandwidth to handle many connections and TCP requests.
- Keep a close eye on network usage.
5.5.3 RAM
- Kafka benefits significantly from the page cache, which utilizes your RAM.
- To understand RAM in Kafka, you need to understand two parts: the Java heap for the Kafka process and the remaining RAM used by the OS page cache.
- Production Kafka machines should have at least 8GB of RAM (16GB or 32GB per broker is common).
- When launching Kafka, you specify Kafka heap options (KAFKA_HEAP_OPTS environment variable). Set a maximum (-Xmx) of 4GB for the Kafka heap to start with, using:
export KAFKA_HEAP_OPTS="-Xmx4g". - Do not set the starting heap size (-Xms); let the heap grow over time and monitor it to determine if you need to increase -Xmx.
5.5.4 OS Page Cache
- The remaining RAM is automatically used for the Linux OS Page Cache, buffering data to the disk, which is what gives Kafka its remarkable performance.
- Make sure swapping is disabled for Kafka entirely.
5.5.5 CPU
- CPU is typically not a performance bottleneck in Kafka because Kafka does not parse any messages. However, under certain circumstances, it can become one.
- If SSL is enabled, Kafka must encrypt and decrypt every payload, increasing CPU load.
- Compression can be CPU-bound if you force Kafka to do it. It is better to allow your producer and consumer to handle compression.
- Keep an eye on Garbage Collection over time to ensure the pauses aren’t too long.
5.5.6 OS
- Increase the file descriptor limits (start with at least 100,000).
- Ideally, only Kafka should be running on your Operating System; anything else could slow down the machine.
6. Important Factors Impacting Kafka
Apart from the aforementioned factors, certain other aspects can impact Kafka’s performance:
- Use Java 8 for optimal performance.
- You might need to tune the GC implementation for better memory management.
- Set Kafka quotas to prevent unexpected spikes in usage. This helps ensure stable performance over time.
7. Running Kafka on AWS Production
Running Kafka on AWS requires careful configuration to ensure optimal performance. Here are some useful resources that provide in-depth details on deploying Apache Kafka on AWS:
- Design and Deployment Considerations for Deploying Apache Kafka on AWS
- Deploying Apache Kafka on AWS Elastic Block Store (EBS)
Key points to consider:
- Distribute your instances across different availability zones for redundancy and high availability.
- Use st1 EBS volumes for the best price-to-performance ratio.
- If scalability is needed, mount multiple EBS volumes to the same broker.
- If using EBS, utilize EBS-optimized instances such as r4.xlarge or m4.2xlarge. Smaller instances may result in performance degradation.
- Establish DNS names or fixed IPs for your brokers to ensure your clients are not affected if you recycle your EC2 instances.
Instance types for EBS:
| Instance | vCPU | Mem (GiB) | Storage | Dedicated EBS Bandwidth (Mbps) | Network Performance |
|---|---|---|---|---|---|
| m4.large | 2 | 8 | EBS-only | 450 | Moderate |
| m4.xlarge | 4 | 16 | EBS-only | 750 | High |
| m4.2xlarge | 8 | 32 | EBS-only | 1,000 | High |
| m4.4xlarge | 16 | 64 | EBS-only | 2,000 | High |
| m4.10xlarge | 40 | 160 | EBS-only | 4,000 | 10 Gigabit |
| m4.16xlarge | 64 | 256 | EBS-only | 10,000 | 25 Gigabit |
Instance types for high memory needs:
| Instance | vCPU | Mem (GiB) | Storage | Networking Performance |
|---|---|---|---|---|
| r4.large | 2 | 15.25 | EBS-Only | Up to 10 |
| r4.xlarge | 4 | 30.5 | EBS-Only | Up to 10 |
| r4.2xlarge | 8 | 61 | EBS-Only | Up to 10 |
| r4.4xlarge | 16 | 122 | EBS-Only | Up to 10 |
| r4.8xlarge | 32 | 244 | EBS-Only | 10 |
| r4.16xlarge | 64 | 488 | EBS-Only | 25 |
8. How to Change Kafka Broker Configuration
Changing Kafka Broker configuration involves updating the server.properties file, stopping and then restarting the Kafka service. Below is an example of how to disable unclean leader elections:
#!/bin/bash
# Add the new setting to server.properties
echo "unclean.leader.election.enable=false" >> config/server.properties
# Stop the Kafka service
sudo service kafka stop
# Restart the Kafka service
sudo service kafka start
# Check the logs to confirm the changes
cat logs/server.log | grep unclean.leader9. Important Parameters to be Aware of
There are numerous parameters you can adjust in Apache Kafka based on your specific requirements. Here are some important ones to be aware of:
auto.create.topics.enable=true– Set to false in production.background.threads=10– Increase if you have a powerful CPU.delete.topic.enable=false– Decide based on your use case.log.flush.interval.messages– Do not change. Let your OS handle it.log.retention hours=168– Adjust according to your retention requirements.message.max.bytes=1000012– Increase if you need more than 1MB.min.insync.replicas=1– Set to 2 for extra safety.num.io.threads=8– Increase if network I/O is a bottleneck.num.network.threads=3– Increase if network I/O is a bottleneck.num.recovery.threads.per.data.dir=1– Set to the number of disks.num.replica.fetchers=1– Increase if your replicas are lagging.offsets.retention.minutes=1440– Offsets are lost after 24 hours.unclean.leader.election.enable=true– Set to false to prevent data loss.zookeeper.session.timeout.ms=6000– Increase if you experience frequent timeouts.broker.rack=null– Set to your AWS availability zone.default.replication.factor=1– Set to 2 or 3 in a Kafka cluster.num.partitions=1– Set from 3 to 6 in your cluster.quota.producer.default=10485760– Set quota to 10MB/s.quota.consumer.default=10485760– Set quota to 10MB/s.
For a full list of broker configurations, visit the Apache Kafka documentation.
10. Installing Kafka Topics UI
Kafka Topics UI is a tool that allows you to view topic data. It reads data from Kafka REST Proxy and provides a UI to display it.
Below is an example configuration file to set up Kafka Topics UI using Docker Compose, which includes Confluent Schema Registry and Confluent REST Proxy:
kafka-topics-ui-docker-compose.yml
version: '2'
services:
confluent-schema-registry:
image: confluentinc/cp-schema-registry:3.2.1
network_mode: host
environment:
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
SCHEMA_REGISTRY_HOST_NAME: "54.206.91.106"
restart: always
confluent-rest-proxy:
image: confluentinc/cp-kafka-rest:3.2.1
network_mode: host
environment:
KAFKA_REST_BOOTSTRAP_SERVERS: kafka1:9092,kafka2:9092,kafka3:9092
KAFKA_REST_ZOOKEEPER_CONNECT: zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka
KAFKA_REST_LISTENERS: http://0.0.0.0:8082/
KAFKA_REST_SCHEMA_REGISTRY_URL: http://localhost:8081/
KAFKA_REST_HOST_NAME: "54.206.91.106"
depends_on:
- confluent-schema-registry
restart: always
kafka-topics-ui:
image: landoop/kafka-topics-ui:0.9.2
network_mode: host
environment:
KAFKA_REST_PROXY_URL: http://localhost:8082
PROXY: "TRUE"
depends_on:
- confluent-rest-proxy
restart: alwaysReplace "54.206.91.106" with the IP address of your server in both SCHEMA_REGISTRY_HOST_NAME and KAFKA_REST_HOST_NAME settings.
After creating this configuration, you can start Kafka Topics UI with the following command:
#!/bin/bash
# Open the kafka-topics-ui-docker-compose.yml file
nano kafka-topics-ui-docker-compose.yml
# Launch Kafka Topics UI
docker-compose -f kafka-topics-ui-docker-compose.yml up -dThis command launches the Kafka Topics UI in detached mode. To view the logs, use the command docker-compose -f kafka-topics-ui-docker-compose.yml logs -f.
Remember to install Docker and Docker Compose if you have not done so already. You will also need to make sure you have a running Kafka cluster with the appropriate services accessible.
Conclusion
Running Kafka in production requires careful planning and understanding of its operation and various configuration settings. This blog post aimed to provide a comprehensive guide on setting up, configuring, and monitoring Kafka clusters for optimal performance. We went through various critical aspects like disk I/O, network considerations, memory utilization, OS Page Cache, CPU usage, and OS configurations.
We also discussed how to tune the JVM settings for Kafka to use the memory effectively. Moreover, we elaborated on how Kafka can be deployed in AWS production environments, emphasizing instance selection, the use of EBS volumes, and spreading instances across availability zones.
We further dived into broker configuration changes, shedding light on essential parameters for a well-functioning Kafka setup. Lastly, we covered how to install Kafka Topics UI for a better visualization and understanding of your Kafka topics.
Operating Kafka in production is not a simple task and may require continuous tuning and monitoring based on your application needs and traffic patterns. It is essential to keep an eye on the performance metrics and adjust configurations as required. Regular monitoring and proactively addressing any potential issues will help maintain the health and performance of your Kafka clusters.
Remember, every Kafka deployment is unique, and there’s no one-size-fits-all configuration. Understand your application, understand Kafka, and make the right choices.



{kind=link}
{kind=link}
{kind=link}